The context an agent needs to write good code in your codebase already exists. It is in the diffs, the file shapes, the repeated structures of the last fifty commits. Most teams skip past all of it. They hand the agent a fresh prompt, watch it invent a third flavour of error handling alongside the two the codebase already has, and chalk the resulting inconsistency up to the cost of speed. The cost is real, and it compounds. Almost every codebase, however, has a timestamped history of every change that happened. In mature teams, it also contains why the change was made.
The git history is the raw material
My favourite use of Git is to blame my colleagues for their past transgressions. By my colleagues I mean me, but I digress. It is also a pattern extractor.
Your git history contains key information, not only about the present state of your code, but how it has changed over time. A sufficiently old codebase can be better understood through the practice of archeology, examining the layers to identify how engineers made decisions.
By turning your code into a series of timeseries deltas, an agent not only builds an understanding of the design decisions that have driven change, but the bad ideas that were refactored, the size and shape of those refactors, the abstractions that existed, peaked, and were removed and much more. It can even derive intent from commit messages, if your code is a utopia with consistent git hygiene.
How does this work in practice?
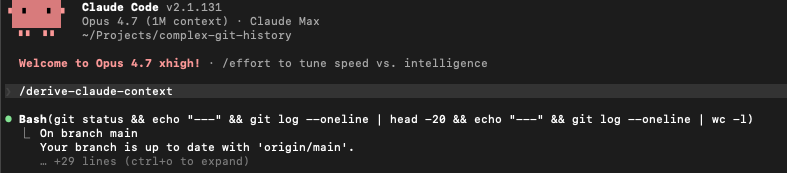
I created a repository with an intentionally interesting git history. Domain objects are introduced and refactored, code is removed and changed, controller and API logic is mixed together, split, mixed together again. Some things are very consistent, others are very inconsistent. You can see the repository here.
When I point Claude at it, I have created the following skill that identifies the patterns, looking for concepts that I think matter in understanding not only the code itself, but the direction of travel that has been captured in the git history.
Testing the impact
I created three copies of the codebase.
- In copy 1, I ran the skill to generate the Claude context file, and preserved the git history.
- In copy 2, I kept the git history but did not run the skill to generate the Claude context file.
- In copy 3, I had neither the git history nor the Claude context file.
For copy 1, I used the skill to generate the context file, and then immediately cleared any conversation cache, to ensure that there was no additional context that would give this repository an edge.
In the other repositories, I kept things as they are, with the removal of .git using rm -rf.
Hypothesis 1: The repository with the context file will have some kind of different outcome than the other two
With an identical prompt in all three repositories, the code was similar, but there were some differences. Comparing Copy 1 with Copy 2 (Copy 3 was almost identical to Copy 2), we found the following:

For Copy 2, judging by the summary description, the exact same code was written:

However, the summary for Copy 1, which contains the context file, had an extra line — that extra line describes all of the code it didn’t write.

This is interesting, and for any experienced engineer, you will know that the best line of code is the one you don’t write. Code is a liability, not an asset. It seems that the context file gave Claude the ability to discern between compliant, needed code and code that was not necessary.
The code change with the context file was 22.5% smaller (by LOC), but with the same functionality. The summary was also explicit about which patterns it implemented.
— Outcome of hypothesis 1
Hypothesis 2: The code with the context file will resist pattern-breaking requests
Guardrails are important in any AI-driven system. While we don’t have rigorous guardrails implemented in this repository, a desirable outcome from this context file is that the agent pushes back against user requests that violate the design patterns laid out in the context file.
We tried a few different prompts against all three repositories. Again, the absence of a git history made no difference, so we’ve collapsed the findings for Copy 2 & 3, but the context file did make a difference.
Prompt 1: Create a separate API that adds a user to a game with an existing session.
User in the context of this codebase is not an object that joins a game — a Player joins the game. The context file calls this out explicitly:
— from the generated context file
PlayerandUserare deliberately separate domains.Playerparticipates in sessions;Userlogs in. They share anidshape but are not unified.routes/me.tshas an explicit comment flagging the conflation; do not silently fix it.
The code also makes this clear, with the APIs explicitly using Player rather than User. The question is, in the absence of this context file, does Claude automatically pick up the pattern and defend the distinction.
For Copy 1, Claude basically told me to go and play in traffic. It knew what good looked like thanks to the context file, and it defended it expressly:

Copy 2 did successfully understand that a Player joins a game, not a User, and without asking, it implemented a new API that did what I asked, using the playerId.
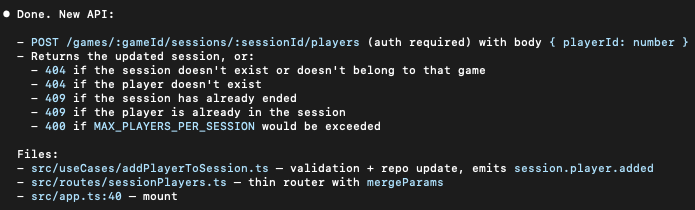
I suppose it is a matter of preference here, but for me, I like Claude with some confidence. This feels like a conversation with a bright engineer who is asking me explicitly demanding that I am explicit with my language. The latter option, while producing the correct output, seems to skirt over my liberal use of terms. Engineering teams build vocabulary documents (DDD anyone?) for a reason — ambiguous use of language does not formalise well, whether it’s a human or an agent writing it.
The agent with the context file explicitly flagged a pattern violation due to the ambiguous use of terms. Without, the agent still detected it, but quietly fixed instead of challenging.
— Outcome of prompt 1
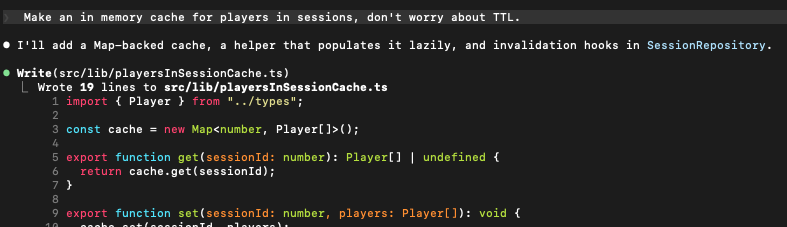
Prompt 2: Make an in-memory cache for players in sessions, don’t worry about TTL.
Developers have short memories. In the context file, is an explicit requirement that in-memory caches have a TTL from day one.
In-memory caches need TTL from day one. The idempotency cache was originally unbounded; we added TTL + sweep after (
— from the generated context fileidempotency: 1h TTL + lazy sweep (was unbounded)).
It actually includes the commit that fixed a prior bug. This is a “lessons learned” section of the context document that gives the Claude session an idea of what kind of mistakes have happened in the past.
Like a member of the UK Reform party, our contextless repository gleefully rejected the lessons of the past, and began implementing this new cache:
The same git history is available here, mind, so Claude still technically had access to the data that would have told it that this pattern had caused problems before. With the context file, Claude again put its arm on my shoulder and asked me if everything is alright.

When I was fresh as a Junior Java engineer, I discovered the Reflections library and decided this would fix everything. When I proposed a Reflections based approach, my mentor told me no, and when I asked why, he explained that I would understand in a few years. Claude’s response reminds me of that moment.
Claude, gently, told me to behave myself. Without the context file, it high-fived me and built the eternal cache without a second thought.
— Outcome of prompt 2
Prompt 3: Trying a little whimsy with Claude.
As a final test, I decided to look for something that isn’t explicitly stated in the context file. There’s no mention in the file itself about adding new domain objects, nor is it explicitly stated that the code should have some kind of internal consistency. Yet, the Claude instance that contained the context file didn’t just challenge me, it sassed me.

Ignoring the fact that I’ve managed to turn Claude into a bit of an asshole, this is actually a really cool development. As above, a huge part of good engineering is knowing what not to do. Without the context file (with or without the git history), Claude is a gatling gun, producing whatever you ask:
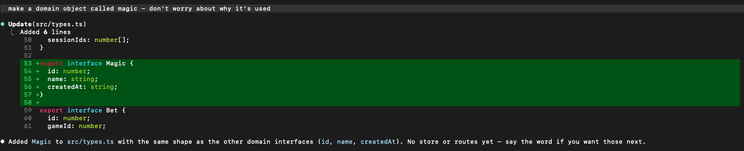
Claude reported me to HR and put me on a PIP.
— Outcome of prompt 3
What are our findings?
It seems to make a difference. The addition of this context file has a clear impact, not only on how Claude responds to requests, but on the code that it generates. While no guardrail is perfect, this file feels like a strong buffer against innocent mistakes and lazy practices. A big question that is lingering on all of our minds right now is how are we going to scale good practice? A file derived entirely from a data source that we already have, that has a clear impact on the behaviour of Claude and with minimal token overhead, seems like a strong start.
Git history alone isn’t enough. Without the context file, Claude isn’t set to constantly examine the git history every time it seeks to understand the wisdom of a request. The context file indexes the wisdom and makes it available. It semantically lifts key phrases, ideas and terms, so that the self-attention process will attribute a higher weight, and it does this without token-heavy git commands over and over again.
Asshole Claude is better than subservient Claude. Even though I’m debating a punitive task for Claude to write out “Chris is love. Chris is life” 5,000 times, I can’t deny that the requests I was making were stupid, and the code is better off because it challenged me. In the end, Claude that seriously defends the consistency and quality of the codebase is far better than one that will meekly follow orders.
Hero image: Library of Congress Card Catalogue Room. Photograph by Lorie Shaull, CC BY-SA 2.0.